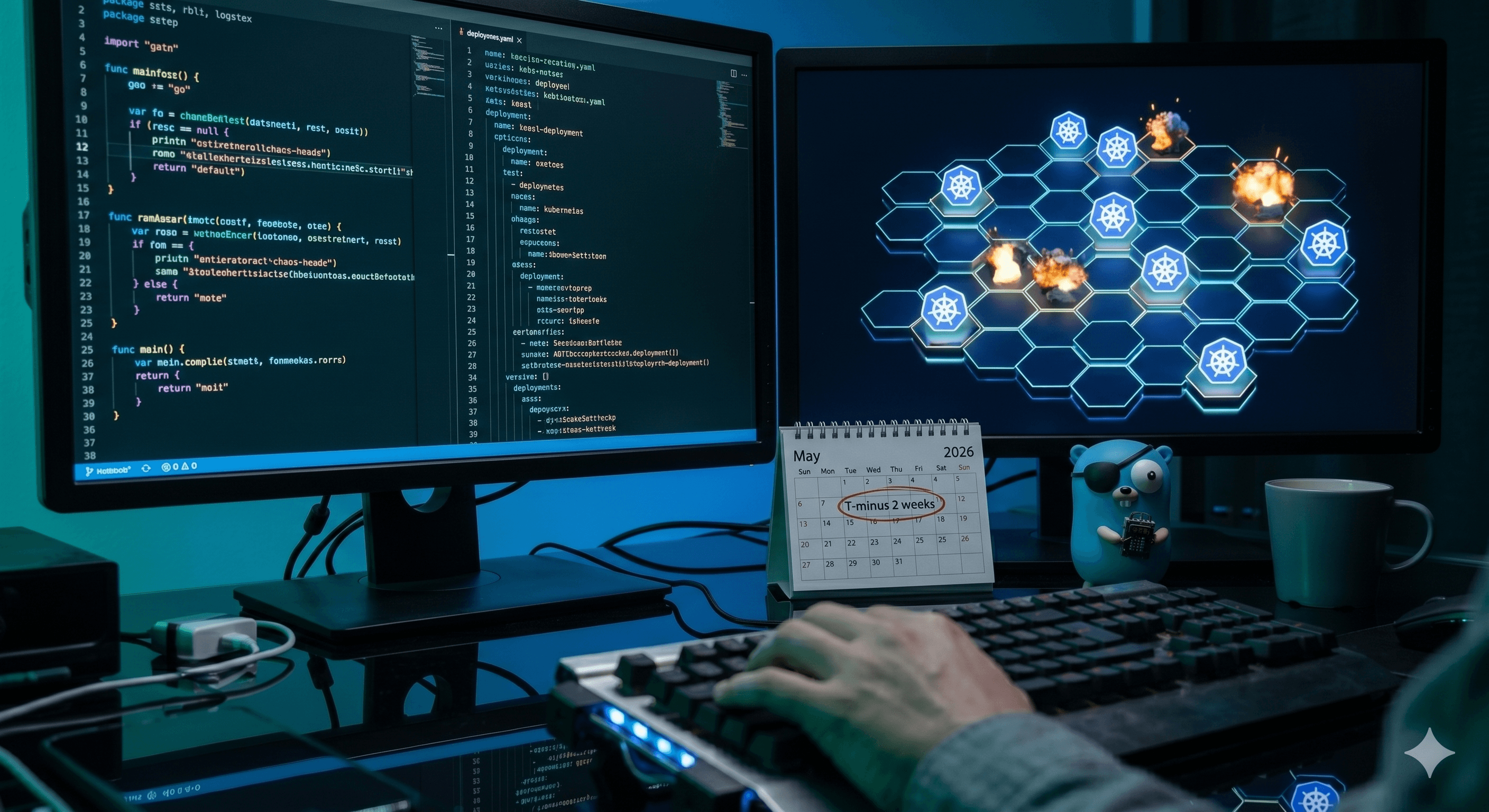
K8s Chaos Battleship: Das Making-Of des unbesiegbaren Clusters
Ein detaillierter Blick hinter die Kulissen unseres interaktiven Chaos Engineering Experiments für die Cloudland 2026 – gebaut mit Go, FluxCD und viel Zerstörungswut.
Mehr lesen

Ich argumentiere, warum ich in Go-Projekten oft auf einen großen ORM verzichte und stattdessen auf SQL-nahe Bibliotheken für maximale Kontrolle und Performance setze.
In vielen modernen Softwareprojekten ist der Einsatz eines Object-Relational Mappers (ORM) wie GORM in Go oder Hibernate in Java der Standard. Doch gerade in der Go-Welt gibt es eine starke Strömung, die “Plain SQL” oder SQL-nahe Bibliotheken bevorzugt. In diesem Beitrag erkläre ich, warum ich in meinen Projekten oft auf schwere ORMs verzichte und wie ich stattdessen performante Daten-Schichten baue.
Go ist eine Sprache, die Explizitheit und Einfachheit schätzt. Ein ORM hingegen führt oft eine komplexe Abstraktionsschicht ein, die versucht, die relationale Natur der Datenbank vor dem Entwickler zu verbergen. Dies führt häufig zu:
Anstatt eines Full-Featured ORM setze ich auf Bibliotheken, die SQL als erstklassigen Bürger behandeln:
database/sql bleiben möchte, aber komfortables Mapping von Zeilen auf Structs benötige, ist sqlx die perfekte Wahl.Ein besonders spannendes Werkzeug, das ich in letzter Zeit immer öfter einsetze, ist sqlc. Hierbei schreibt man natives SQL, und sqlc generiert daraus typsicheren Go-Code.
Rows.Scan() aufrufen zu müssen. Es ist quasi das Beste aus beiden Welten.PostgreSQLs Fähigkeit, JSONB-Daten effizient zu verarbeiten, passt hervorragend zu Go. In meinen Services speichere ich oft flexiblere Datenstrukturen in JSONB-Spalten und mappe diese direkt auf Go-Structs. Dank der hervorragenden Unterstützung in pgx ist dies performant und einfach umzusetzen.
Für kleine Prototypen mag ein ORM Zeit sparen. Doch sobald eine Anwendung skaliert und Performance sowie Wartbarkeit in den Vordergrund rücken, zahlt sich der SQL-nahe Ansatz aus. Die Kontrolle über die Abfragen und das klare Verständnis der Datenflüsse machen Go-Backends robuster und effizienter.
Optimieren Sie gerade Ihre Daten-Schicht in Go oder planen eine Migration auf PostgreSQL?
Ich unterstütze Sie dabei, eine performante Architektur ohne unnötigen Overhead aufzubauen. Kontaktieren Sie mich für ein Architektur-Review.
Ob Sie ein fertiges Fundament suchen oder eine maßgeschneiderte Individuallösung benötigen – ich unterstütze Sie bei Ihrem Vorhaben.
Bleiben Sie auf dem Laufenden mit aktuellen Beiträgen zu DevSecOps, Webentwicklung, Smart Home und mehr.
Zum BlogEin detaillierter Blick hinter die Kulissen unseres interaktiven Chaos Engineering Experiments für die Cloudland 2026 – gebaut mit Go, FluxCD und viel Zerstörungswut.

Ein technischer Leitfaden zur Konfiguration von Streaming-Replikation in PostgreSQL, um die Ausfallsicherheit zu erhöhen und die Lese-Last zu verteilen.

Ich stelle meine Strategie vor, um IT-Dokumentation nicht veralten zu lassen, indem ich sie eng an den Entwicklungsprozess in Git anbinde.

Ich zeige, wie ich eine eigene, interne Certificate Authority (CA) aufsetze, um die Kommunikation zwischen Microservices mit TLS abzusichern.