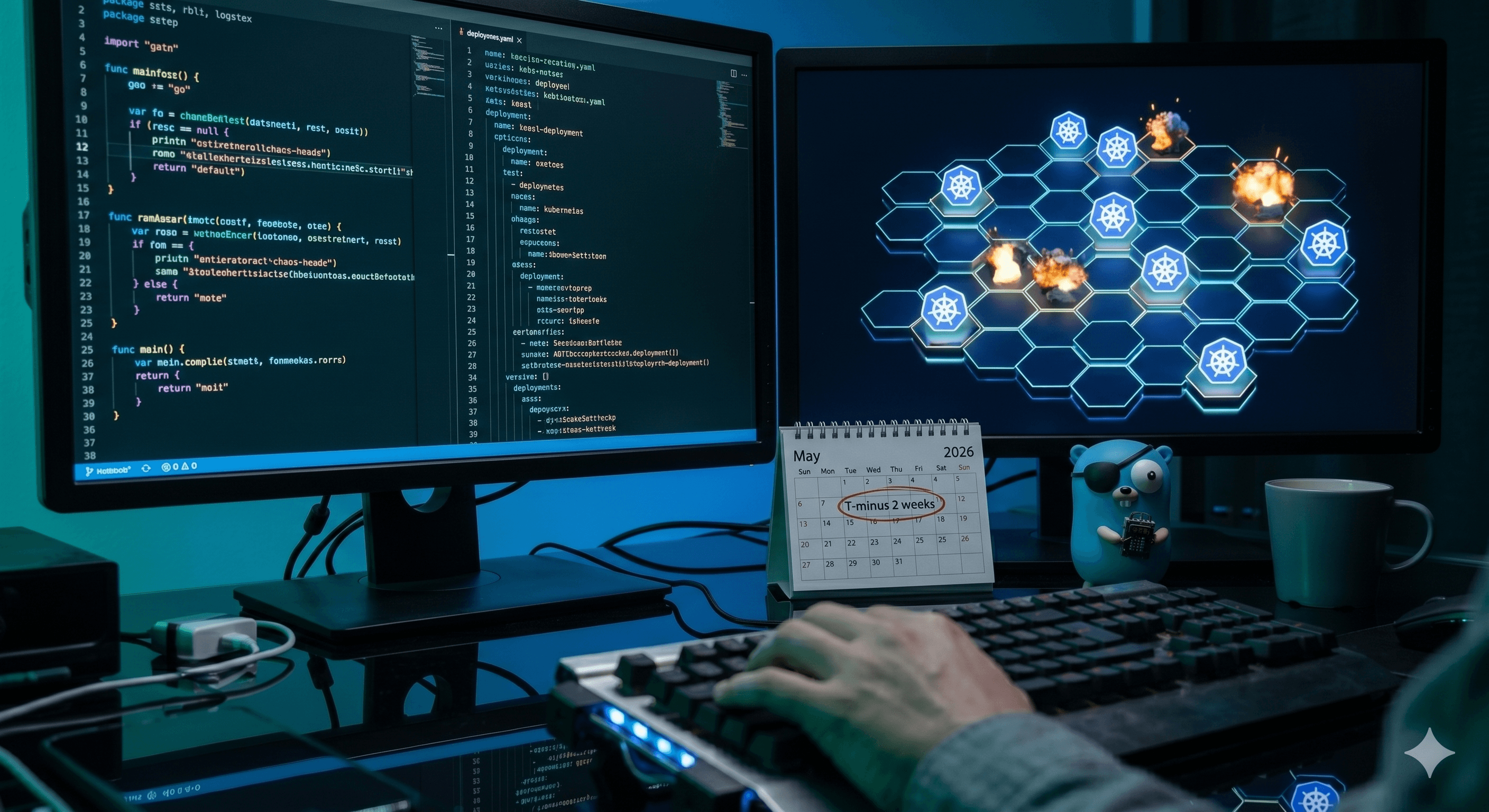
K8s Chaos Battleship: Das Making-Of des unbesiegbaren Clusters
Ein detaillierter Blick hinter die Kulissen unseres interaktiven Chaos Engineering Experiments für die Cloudland 2026 – gebaut mit Go, FluxCD und viel Zerstörungswut.
Mehr lesen
Eine praktische Anleitung, wie ich Go-Anwendungen instrumentiere und ein Monitoring-Dashboard mit Prometheus und Grafana aufsetze, um die Systemgesundheit im Blick zu behalten.
In einer Microservice-Architektur ist “Blindflug” keine Option. Wir müssen jederzeit wissen, wie viele Anfragen pro Sekunde eingehen, wie hoch die Fehlerquote ist und wo Latenzen entstehen. Go eignet sich hervorragend für das Monitoring, da es leichtgewichtige Metriken-Libraries bietet, die kaum Performance-Overhead verursachen. In diesem Beitrag zeige ich Ihnen meinen Standard-Stack für das Monitoring von Go-Services: Prometheus und Grafana.
Anstatt Daten aktiv an einen Server zu senden, nutzt Prometheus ein Pull-Modell. Der Go-Service bietet einen HTTP-Endpunkt (meist /metrics) an, von dem Prometheus die Daten abholt.
http_requests_total).active_goroutines).Ich konzentriere mich beim Monitoring auf die vier wichtigsten Signale nach dem SRE-Modell von Google:
Rohdaten in Prometheus sind nützlich, aber erst in Grafana werden sie zu handhabbarem Wissen.
Monitoring ist nutzlos, wenn niemand auf die Daten schaut.
Ein robuster Monitoring-Stack mit Go, Prometheus und Grafana ist die Lebensversicherung für Ihre Microservices. Er ermöglicht es uns, Probleme zu erkennen, bevor der Kunde sie bemerkt, und fundierte Entscheidungen über Skalierung und Optimierung zu treffen. In einer Welt verteilter Systeme ist Observability kein Zusatz-Feature, sondern ein Kernbestandteil der Architektur.
Haben Sie den Überblick über Ihre Microservices verloren?
Ich unterstütze Sie bei der Einführung von professionellem Monitoring und Alerting für Ihre Go-Infrastruktur. Lassen Sie uns Ihre System-Transparenz erhöhen.
Ob Sie ein fertiges Fundament suchen oder eine maßgeschneiderte Individuallösung benötigen – ich unterstütze Sie bei Ihrem Vorhaben.
Bleiben Sie auf dem Laufenden mit aktuellen Beiträgen zu DevSecOps, Webentwicklung, Smart Home und mehr.
Zum BlogEin detaillierter Blick hinter die Kulissen unseres interaktiven Chaos Engineering Experiments für die Cloudland 2026 – gebaut mit Go, FluxCD und viel Zerstörungswut.

Ein technischer Leitfaden zur Konfiguration von Streaming-Replikation in PostgreSQL, um die Ausfallsicherheit zu erhöhen und die Lese-Last zu verteilen.

Ich stelle meine Strategie vor, um IT-Dokumentation nicht veralten zu lassen, indem ich sie eng an den Entwicklungsprozess in Git anbinde.

Ich zeige, wie ich eine eigene, interne Certificate Authority (CA) aufsetze, um die Kommunikation zwischen Microservices mit TLS abzusichern.