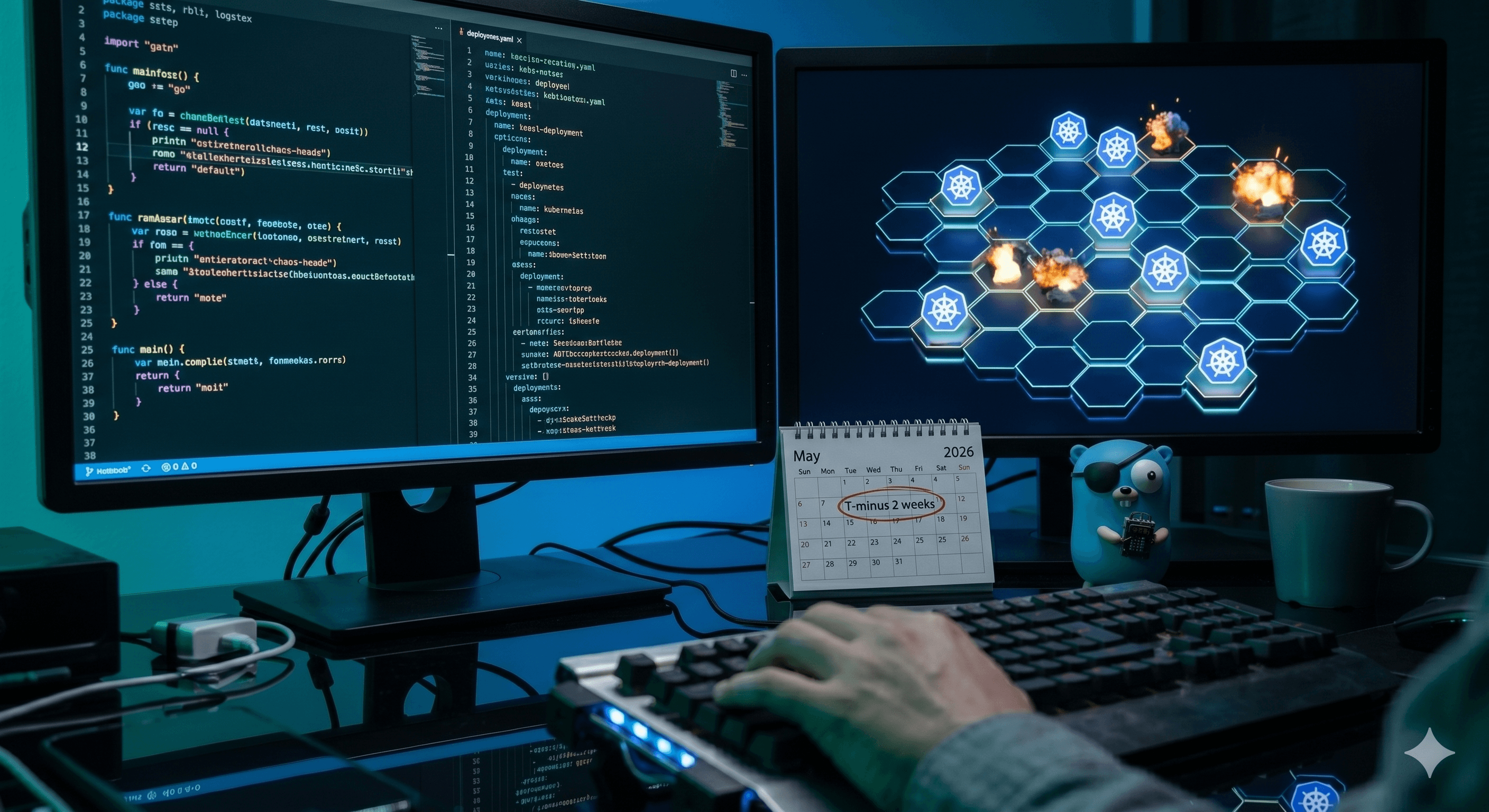
K8s Chaos Battleship: Das Making-Of des unbesiegbaren Clusters
Ein detaillierter Blick hinter die Kulissen unseres interaktiven Chaos Engineering Experiments für die Cloudland 2026 – gebaut mit Go, FluxCD und viel Zerstörungswut.
Mehr lesen

Warum strukturiertes Logging in Microservice-Architekturen überlebenswichtig ist und wie ich es in Go mit slog umsetze.
In einer verteilten Microservice-Architektur ist das Auffinden von Fehlern ohne eine durchdachte Logging-Strategie die sprichwörtliche Suche nach der Nadel im Heuhaufen. Einfache Text-Logs, die man mit grep durchsucht, stoßen bei Hunderten von Containern schnell an ihre Grenzen. Wir brauchen Daten, die Maschinen lesen, aggregieren und korrelieren können. In diesem Beitrag zeige ich Ihnen, wie ich mit Go’s modernem slog Paket ein robustes Logging-Framework aufbaue.
Menschlich lesbare Logs sind wunderbar für die lokale Entwicklung, aber in Produktion brauchen wir Struktur.
"user_id": 123, "request_duration_ms": 45). Dies erlaubt blitzschnelle Filterungen und Aggregationen über Milliarden von Log-Einträgen hinweg.Das größte Problem in Microservices ist es, einen einzelnen Nutzer-Request über mehrere Dienste hinweg zu verfolgen.
context.Context) an alle Funktionen und sogar an nachgelagerte Services weitergereicht.slog kann ich diese ID automatisch in jeden Log-Eintrag schreiben lassen. Wenn ein Fehler auftritt, kann ich mit einer einzigen Suche alle beteiligten Dienste und Aktionen identifizieren, die zu diesem Problem geführt haben.Ich sehe oft Projekte, die alles als ERROR loggen oder bei denen DEBUG Logs die Festplatten in Produktion füllen. Eine klare Strategie ist wichtig:
Logging darf die Anwendung nicht ausbremsen. slog wurde mit Fokus auf Performance entwickelt.
slog die Speicherallokationen.Ein exzellentes Logging-Framework ist kein Luxus, sondern die Grundlage für den stabilen Betrieb moderner Software. Durch den Einsatz von strukturiertem JSON-Logging, die konsequente Nutzung von Context-Informationen und das richtige Tooling in Go (slog) schaffen wir die notwendige Transparenz, um Probleme zu lösen, bevor der Nutzer sie bemerkt.
Haben Sie Schwierigkeiten, Fehler in Ihrer Microservice-Landschaft zu finden oder ist Ihr aktuelles Logging unübersichtlich?
Ich helfe Ihnen bei der Implementierung einer modernen Observability-Strategie und dem Aufbau eines performanten Logging-Frameworks in Go. Kontaktieren Sie mich für ein Monitoring-Review.
Ob Sie ein fertiges Fundament suchen oder eine maßgeschneiderte Individuallösung benötigen – ich unterstütze Sie bei Ihrem Vorhaben.
Bleiben Sie auf dem Laufenden mit aktuellen Beiträgen zu DevSecOps, Webentwicklung, Smart Home und mehr.
Zum BlogEin detaillierter Blick hinter die Kulissen unseres interaktiven Chaos Engineering Experiments für die Cloudland 2026 – gebaut mit Go, FluxCD und viel Zerstörungswut.

Ein technischer Leitfaden zur Konfiguration von Streaming-Replikation in PostgreSQL, um die Ausfallsicherheit zu erhöhen und die Lese-Last zu verteilen.

Ich stelle meine Strategie vor, um IT-Dokumentation nicht veralten zu lassen, indem ich sie eng an den Entwicklungsprozess in Git anbinde.

Ich zeige, wie ich eine eigene, interne Certificate Authority (CA) aufsetze, um die Kommunikation zwischen Microservices mit TLS abzusichern.