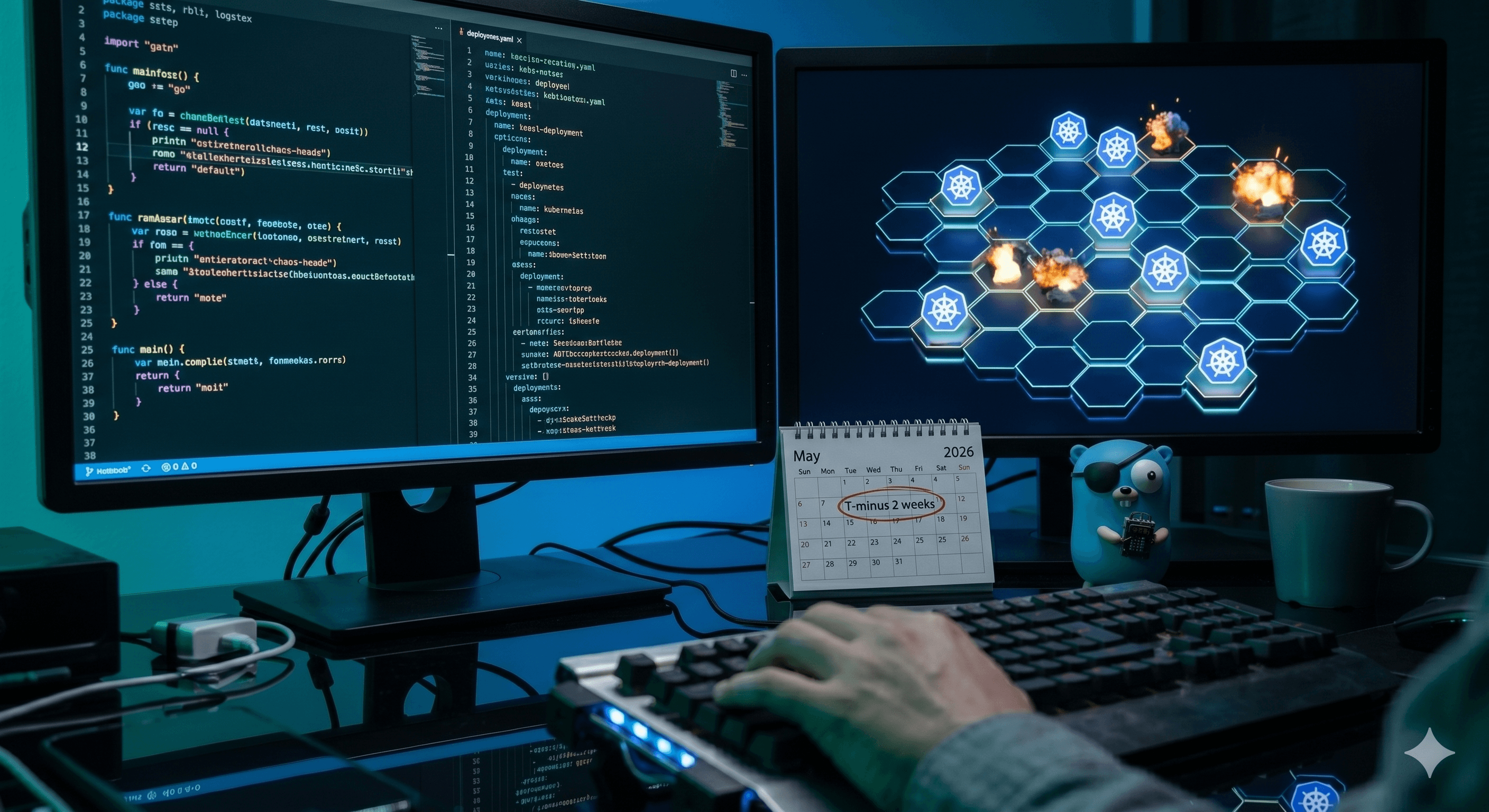
K8s Chaos Battleship: Das Making-Of des unbesiegbaren Clusters
Ein detaillierter Blick hinter die Kulissen unseres interaktiven Chaos Engineering Experiments für die Cloudland 2026 – gebaut mit Go, FluxCD und viel Zerstörungswut.
Mehr lesen

Ich erkläre die Wichtigkeit regelmäßiger Disaster-Recovery-Tests und zeige, wie ich einen solchen Test für eine PostgreSQL-Infrastruktur plane und durchführe.
Ein Backup zu haben, gibt ein beruhigendes Gefühl. Doch in der Krise zählt nicht das Vorhandensein von Backups, sondern die Fähigkeit zur Wiederherstellung. Ein fehlerhaftes Backup-Skript, ein korruptes Dateisystem oder schlichtweg fehlende Dokumentation können im Ernstfall dazu führen, dass ein Unternehmen tagelang stillsteht. Deshalb ist ein regelmäßiger Disaster Recovery (DR) Test für Ihre PostgreSQL-Datenbanken unerlässlich. In diesem Beitrag zeige ich Ihnen mein Vorgehen bei der Prüfung von Notfallplänen.
Bevor wir testen, müssen wir wissen, what wir erreichen wollen.
Ein manueller DR-Test alle sechs Monate reicht nicht aus. Ich automatisiere diesen Prozess.
Der wichtigste Teil meiner PostgreSQL-Strategie ist das Write-Ahead Logging (WAL) Archivierung.
Technik ist das eine, Prozesse das andere. Einmal im Jahr führen wir einen “Gameday” durch.
Ein Disaster Recovery Test ist kein Zeichen von Misstrauen in die eigene Technik, sondern ein Zeichen von Professionalität. Durch die Kombination von automatisierten Wiederherstellungs-Tests und regelmäßigen manuellen Übungen stellen wir sicher, dass PostgreSQL im Ernstfall nicht zum Flaschenhals wird. Wer heute übt, muss morgen in der Krise keine Panik haben.
Ist Ihre Datenbank-Wiederherstellung krisenfest?
Ich unterstütze Sie bei der Konzeption von Backup-Strategien und der Durchführung von Disaster-Recovery-Audits für Ihre PostgreSQL-Infrastruktur. Lassen Sie uns Ihren Notfallplan gemeinsam testen.
Ob Sie ein fertiges Fundament suchen oder eine maßgeschneiderte Individuallösung benötigen – ich unterstütze Sie bei Ihrem Vorhaben.
Bleiben Sie auf dem Laufenden mit aktuellen Beiträgen zu DevSecOps, Webentwicklung, Smart Home und mehr.
Zum BlogEin detaillierter Blick hinter die Kulissen unseres interaktiven Chaos Engineering Experiments für die Cloudland 2026 – gebaut mit Go, FluxCD und viel Zerstörungswut.

Ein technischer Leitfaden zur Konfiguration von Streaming-Replikation in PostgreSQL, um die Ausfallsicherheit zu erhöhen und die Lese-Last zu verteilen.

Ich stelle meine Strategie vor, um IT-Dokumentation nicht veralten zu lassen, indem ich sie eng an den Entwicklungsprozess in Git anbinde.

Ich zeige, wie ich eine eigene, interne Certificate Authority (CA) aufsetze, um die Kommunikation zwischen Microservices mit TLS abzusichern.