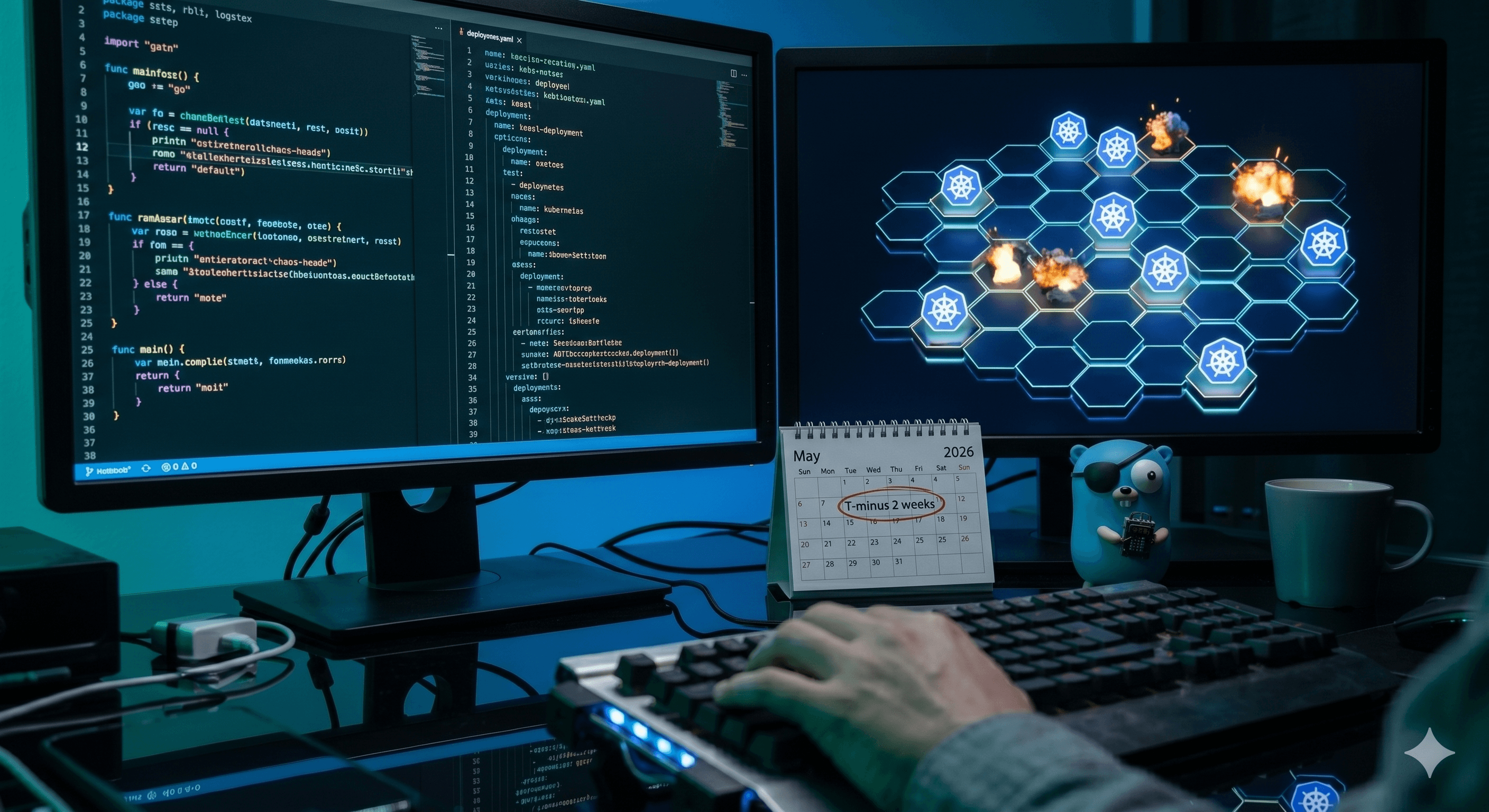
K8s Chaos Battleship: Das Making-Of des unbesiegbaren Clusters
Ein detaillierter Blick hinter die Kulissen unseres interaktiven Chaos Engineering Experiments für die Cloudland 2026 – gebaut mit Go, FluxCD und viel Zerstörungswut.
Mehr lesen

Ein Beitrag zum Thema: Data Governance für Microservices: Wer besitzt welche Daten in einer verteilten Architektur?
Der Wechsel von einem Monolithen zu Microservices bringt viele Vorteile, schafft aber eine gewaltige neue Herausforderung: Die Datenhaltung. In einem Monolithen gibt es meist eine zentrale Datenbank (“Single Source of Truth”). In einer Microservice-Architektur besitzt jeder Service seine eigenen Daten. Ohne klare Regeln (Data Governance) führt das schnell zu redundanten, widersprüchlichen oder verwaisten Datensätzen – ein Albtraum für die Konsistenz und die DSGVO-Compliance. In diesem Beitrag zeige ich Ihnen, wie ich Data Governance in verteilten Systemen strukturiere.
Governance beginnt bei der Verantwortung. Jeder Datensatz muss genau einem “Owner-Service” zugeordnet sein.
CustomerService besitzt die Stammdaten. Der OrderService darf die Lieferadresse zwar anzeigen, muss sie aber bei Änderungen beim CustomerService anfordern.In verteilten Systemen sind klassische Datenbank-Transaktionen über Servicegrenzen hinweg (Two-Phase Commit) langsam und fehleranfällig.
CustomerService ändert, wird ein AddressChanged-Event gefeuert.Daten sind nur so gut wie ihre Definition.
In einer verteilten Architektur ist das Löschen eines Nutzers eine technische Herausforderung.
Microservices ohne Data Governance führen unweigerlich in technische Schulden und rechtliche Risiken. Indem wir klare Owner definieren, auf asynchrone Kommunikation setzen und Verträge zwischen Services strikt einhalten, schaffen wir eine Architektur, die nicht nur technisch skaliert, sondern auch fachlich sauber bleibt.
Haben Sie den Überblick über Ihre Datenflüsse in der Microservice-Landschaft verloren?
Ich helfe Ihnen bei der Definition von Daten-Strategien und der technischen Umsetzung von Governance-Mechanismen. Kontaktieren Sie mich für ein Architektur-Review.
Ob Sie ein fertiges Fundament suchen oder eine maßgeschneiderte Individuallösung benötigen – ich unterstütze Sie bei Ihrem Vorhaben.
Bleiben Sie auf dem Laufenden mit aktuellen Beiträgen zu DevSecOps, Webentwicklung, Smart Home und mehr.
Zum BlogEin detaillierter Blick hinter die Kulissen unseres interaktiven Chaos Engineering Experiments für die Cloudland 2026 – gebaut mit Go, FluxCD und viel Zerstörungswut.

Ein technischer Leitfaden zur Konfiguration von Streaming-Replikation in PostgreSQL, um die Ausfallsicherheit zu erhöhen und die Lese-Last zu verteilen.

Ich stelle meine Strategie vor, um IT-Dokumentation nicht veralten zu lassen, indem ich sie eng an den Entwicklungsprozess in Git anbinde.

Ich zeige, wie ich eine eigene, interne Certificate Authority (CA) aufsetze, um die Kommunikation zwischen Microservices mit TLS abzusichern.