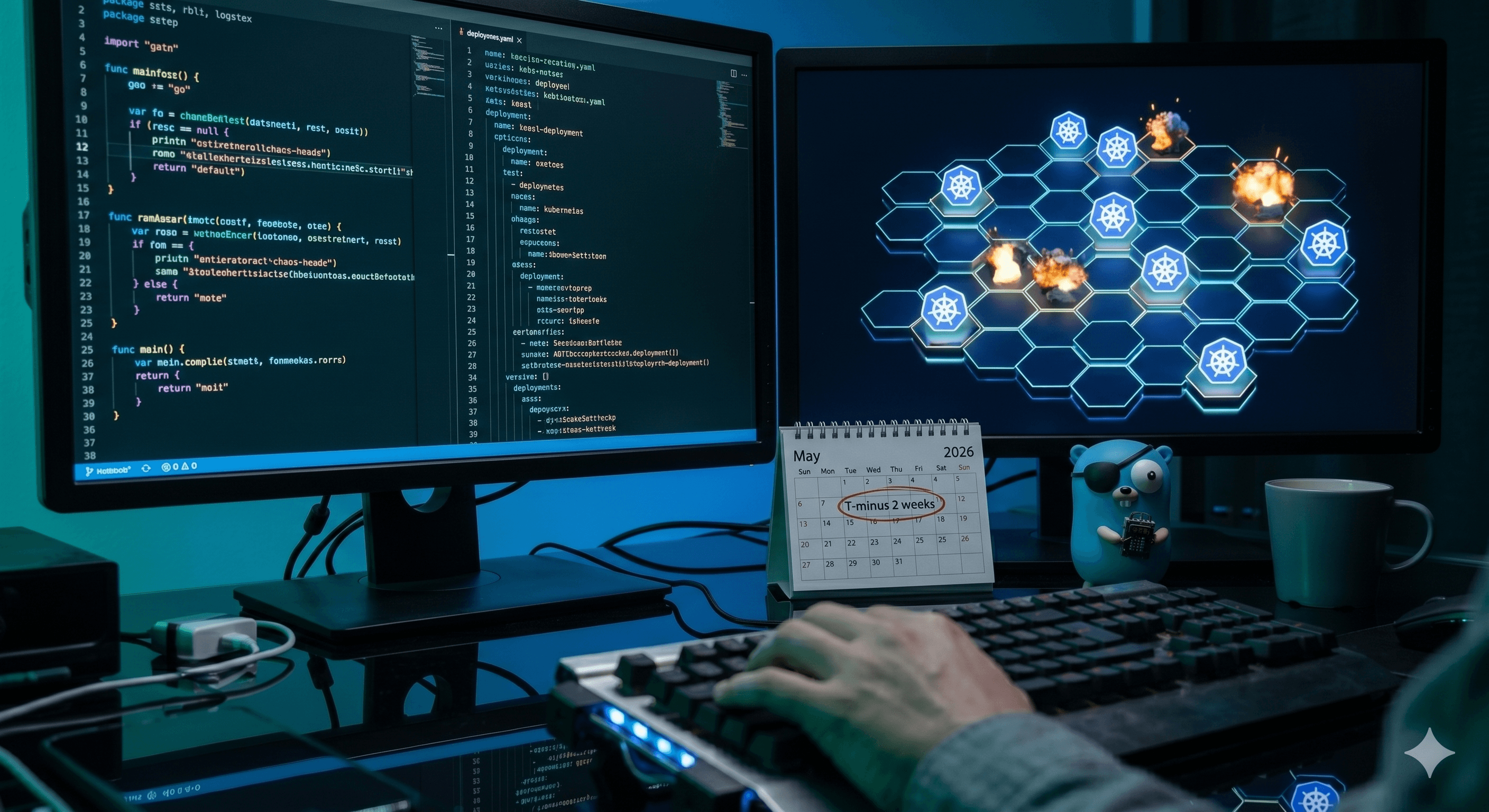
K8s Chaos Battleship: Das Making-Of des unbesiegbaren Clusters
Ein detaillierter Blick hinter die Kulissen unseres interaktiven Chaos Engineering Experiments für die Cloudland 2026 – gebaut mit Go, FluxCD und viel Zerstörungswut.
Mehr lesen

Ein Beitrag zum Thema: Anonymisierung von Daten in PostgreSQL für Testumgebungen: Mein Skript.
Für eine effektive Softwareentwicklung sind realitätsnahe Testdaten unerlässlich. Doch der Einsatz von echten Produktionsdaten in Entwicklungs- oder Testumgebungen ist nicht nur ein hohes Sicherheitsrisiko, sondern verstößt auch direkt gegen die DSGVO. Die Herausforderung besteht darin, die Daten so zu verändern, dass sie keinen Personenbezug mehr zulassen, aber ihre strukturelle Integrität und statistische Relevanz behalten. In diesem Beitrag zeige ich Ihnen mein Vorgehen und ein praktisches Skript zur Anonymisierung von PostgreSQL-Datenbanken.
Es gibt zwei Hauptansätze: Entweder man kopiert die Daten in eine gesicherte Umgebung und anonymisiert sie dort (“In-Place”), oder man anonymisiert sie während des Extraktionsprozesses (“Extract, Transform, Load”).
Bevor das Skript läuft, müssen wir definieren, was geschützt werden muss.
PostgreSQL bietet mächtige Funktionen, um Daten effizient zu transformieren. Hier ein Auszug aus meinem Standard-Skript:
-- Namen durch Zufalls-Strings ersetzen
UPDATE users SET
first_name = 'User_' || id,
last_name = md5(random()::text),
email = 'user_' || id || '@example.test';
-- Adressen verfälschen
UPDATE addresses SET
street = 'Teststraße ' || (random()*100)::int,
city = 'Testhausen';
-- Passwörter zurücksetzen (für Login in Testumgebung)
UPDATE users SET password_hash = '$2a$12$test_hash_hier';Für komplexere Daten nutze ich oft die Erweiterung faker (wenn verfügbar) oder schreibe kleine Go-Utilities, die über das API der Datenbank laufen und konsistentere Zufallsdaten generieren.
Die größte Schwierigkeit ist die Konsistenz über Tabellengrenzen hinweg. Wenn eine user_id in mehreren Tabellen vorkommt, muss sie überall gleich behandelt werden, damit die Anwendung logisch weiterfunktioniert.
hash(id + salt) führt immer zum gleichen anonymen Ergebnis, was die referenzielle Integrität wahrt, ohne den Originalwert preiszugeben.Automatisierte Anonymisierung ist ein Eckpfeiler moderner DevSecOps-Praktiken. Mit einem gut durchdachten Skript und einem klaren Mapping-Prozess lässt sich die Lücke zwischen Datenschutz-Compliance und effizientem Testing schließen. Echte Daten gehören in die Produktion – anonyme Daten in die Entwicklung.
Haben Sie Fragen zur sicheren Handhabung von Testdaten in Ihrem Unternehmen?
Ich helfe Ihnen bei der Implementierung von Anonymisierungs-Pipelines und der Absicherung Ihrer Testumgebungen. Kontaktieren Sie mich für ein Beratungsgespräch.
Ob Sie ein fertiges Fundament suchen oder eine maßgeschneiderte Individuallösung benötigen – ich unterstütze Sie bei Ihrem Vorhaben.
Bleiben Sie auf dem Laufenden mit aktuellen Beiträgen zu DevSecOps, Webentwicklung, Smart Home und mehr.
Zum BlogEin detaillierter Blick hinter die Kulissen unseres interaktiven Chaos Engineering Experiments für die Cloudland 2026 – gebaut mit Go, FluxCD und viel Zerstörungswut.

Ein technischer Leitfaden zur Konfiguration von Streaming-Replikation in PostgreSQL, um die Ausfallsicherheit zu erhöhen und die Lese-Last zu verteilen.

Ich stelle meine Strategie vor, um IT-Dokumentation nicht veralten zu lassen, indem ich sie eng an den Entwicklungsprozess in Git anbinde.

Ich zeige, wie ich eine eigene, interne Certificate Authority (CA) aufsetze, um die Kommunikation zwischen Microservices mit TLS abzusichern.